
データサイエンスは近年、ますます重要度を増しています。19世紀に統計学が確立され、データの収集・分析・解釈が行われるようになると、20世紀にはコンピューターの登場により、飛躍的に発展しました。
今、ビジネス、医療、金融、教育など、さまざまな分野で活用される「データサイエンス」とは何か、データサイエンスの身近な事例、データサイエンティストになるための方法などについてわかりやすく解説します。
目次
データサイエンスとは?簡単に解説
データサイエンスとは、大量のデータの中から価値ある情報を抽出することを目的とした学問分野です。主に
- 統計学
- コンピュータサイエンス
- 機械学習
などの技術を用いて、データの収集・整理・分析・可視化を行います。
データサイエンスの目的は、データから価値を生み出すことです。データを分析することで、新しい発見や予測ができるため、企業や社会の課題を解決する手助けをすることができます。
データサイエンスは、現代の社会で非常に重要な役割を果たしており、将来的には、ますます需要が高まる分野とされています。
【日本のデジタル人材の育成目標】
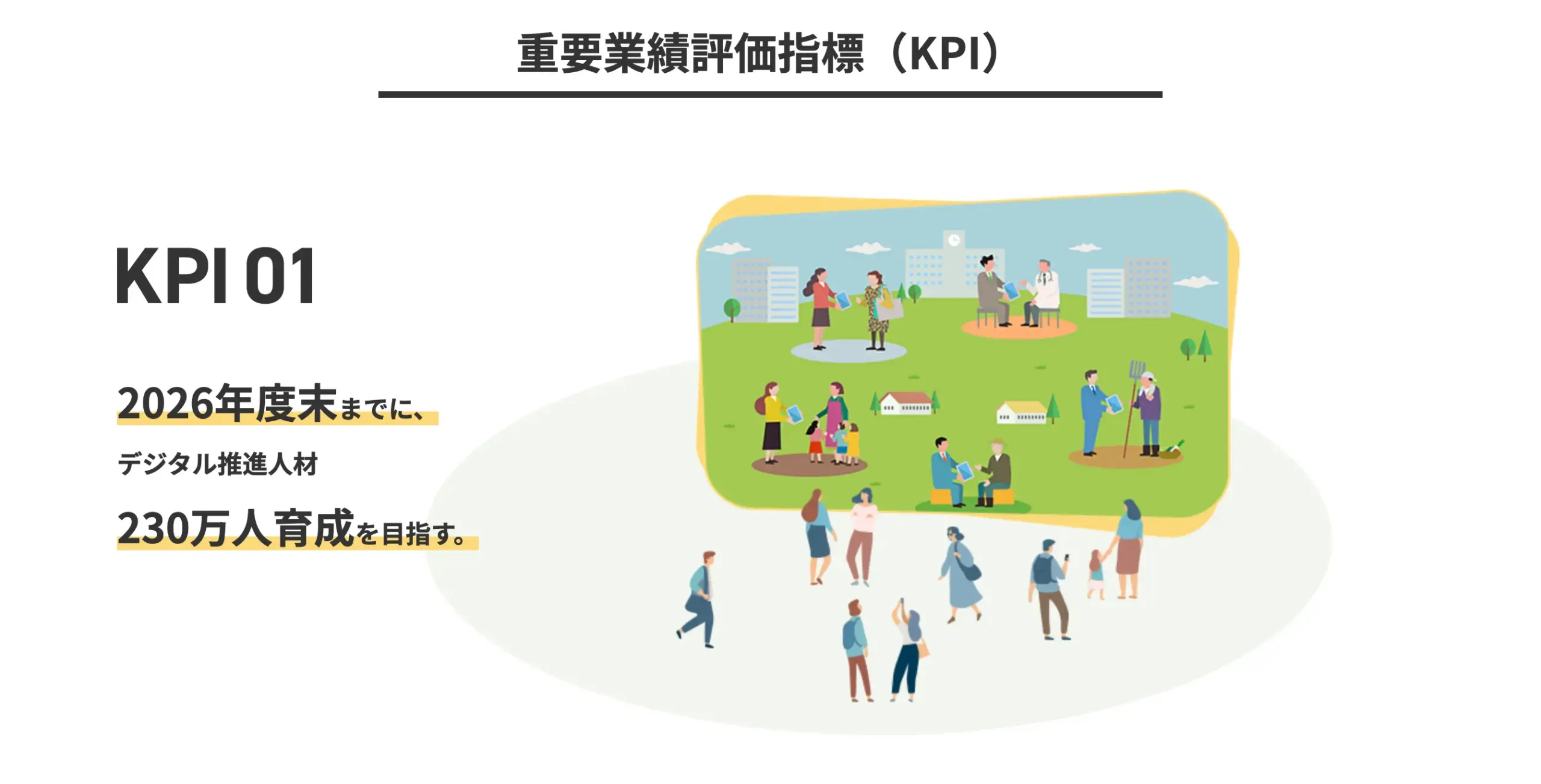
データサイエンス入門
データサイエンス入門では、統計学・プログラミング・AIの基礎を簡単に学び、データを整理・分析して身近な問題解決に役立てる方法を学びます。
例えば、エクセルでのデータ集計や、Pythonを使ったシンプルな分析など、初心者でも始めやすい内容からスタートできます。まずは「データを扱う楽しさ」を知ることが第一歩となります。
データサイエンスとビジネスインテリジェンスとの違い
| データサイエンス | ビジネスインテリジェンス | |
|---|---|---|
| 目的 | 大量のデータから新たな知見を導き出すこと | 既存のデータを分析し、ビジネス上の意思決定を支援すること |
| アプローチ | データから新しいパターンや関係性を見つけ出すことに重点を置く | 既存のデータを使ってビジネスのパフォーマンスを監視し、改善することに重点を置く |
| 対象 | 研究開発や学術的な目的に使用されることが多い | 比較的単純な処理で済むデータに使用されることが多い |
| 処理 | 高度な技術が要求される | 比較的技術が低い |
| 解析手法 | 機械学習、統計解析、自然言語処理などの高度な手法を使用することが多い | 集計、クロス集計、グラフ化などの基本的な手法を使用することが多い |
| 対象者 | データサイエンティスト、研究者、エンジニアなど | マーケティング担当者、経営者、アナリストなど |
| 効果 | より大きなビジネスインパクトをもたらす | ビジネスの現状を把握し、改善策を立案するのに役立つ |
データサイエンスとビジネスインテリジェンスは、どちらもデータを使ってビジネスを改善する分野ですが、その目的と方法にはいくつかの違いがあります。
現在では、ビジネスインテリジェンスの分野でもAIが活用されています。
AIによって、データサイエンス、ビジネスインテリジェンスの両方の分野で、データの収集、分析、可視化、そしてその結果を活用するプロセスのすべてを自動化することができます。これにより、データサイエンティストは、より複雑なデータ分析に集中することができ、ビジネスアナリストは、より重要なことに集中することができるのです。
今後はAIの活用により、データサイエンスとビジネスインテリジェンスの関係性は、より密接なものになるでしょう。
データ分析との違い
| データサイエンス | データ分析 | |
|---|---|---|
| 目的 | データから新しいパターンや関係性を見つけ出す | 既存のデータを分析し、パターンや傾向を見つけ出す |
| アプローチ | 新たな知見を導き出すことに重点を置く | 既存のデータを分析することに重点を置く |
| 対象 | 研究開発や学術的な目的に使用されることが多い | 統計学やビジネス分野で使用されることが多い |
| 処理対象 | 精度が高く、複雑な処理が必要なデータに使用されることが多い | 比較的単純な処理で済むデータに使用されることが多い |
| 解析手法 | 機械学習、統計解析、自然言語処理などの高度な手法を使用することが多い | 統計解析やデータマイニングなどの手法を使用することが多い |
データ分析とは、データから有益な情報を引き出すプロセスです。データ分析は、データサイエンスの一部ですが、データサイエンスよりも比較的技術が低く、ビジネスの現状を把握し、改善策を立案するのに役立ちます。
データサイエンスとデータ分析は、どちらもデータを扱うことを目的とした分野ですが、そのアプローチや目的に違いがあると言えるでしょう。
それぞれの得意分野・不得意分野
| 得意分野 | 不得意分野 | |
|---|---|---|
| データサイエンス | ・データから新しいパターンや関係性を見つけ出す ・機械学習、自然言語処理、画像認識などの高度な技術を使用する | ・既存のデータを分析すること ・統計学やビジネス分野で使用されることが多い単純な処理 |
| ビジネスインテリジェンス | ・データを使って、ビジネスのパフォーマンスを監視し、改善する ・ビジネスにおける意思決定を支援する ・データの収集や可視化、レポート作成などの基本的な処理 | ・大量のデータから新たな知見を導き出すこと ・機械学習や自然言語処理などの高度な技術を使用すること |
| データ分析 | ・データから有益な情報を引き出す ・既存のデータを分析し、パターンや傾向を見つけ出す ・統計学やビジネス分野で使用されることが多い単純な処理 |
データサイエンス、ビジネスインテリジェンス、データ分析の得意分野・不得意分野を表にまとめました。
各分野の得意分野と不得意分野については、個々の専門家や企業によって異なる場合があるため、一概に当てはまるわけではありません。しかし、この特徴を理解したうえで、ビジネスの状況に合わせて、これら3つの分野を組み合わせて使うことが重要です。
次の章では、さらに踏み込んで、データサイエンスのプロジェクト進行について解説します。*1)
データサイエンスのプロジェクト進行について
データサイエンスのプロジェクトは、複雑で時間がかかります。データサイエンスを利用して問題を解決し、目標を達成するためには、一般的に以下のような手順で進めます。
※ただし、プロジェクトによってはステップの順序が異なる場合もあります。
問題の定義とデータ収集
解決したい問題・目的を明確にします。その後、問題解決に必要なデータを収集します。
問題の定義
問題の定義とは、解決したい問題を明確にし、目的を明確にすることです。問題の定義が曖昧であると、適切なデータ収集や分析を行うことができません。問題の定義を行う際には、次の点に注意してください。
- 問題を明確に言葉で表現する。
- 問題の原因を特定する。
- 問題を解決することによるメリットを明確にする。
データ収集
データ収集には、以下のような方法があります。
- オンライン調査やアンケート
- センサーデータの収集
- ウェブスクレイピング
- データベースからのデータエクスポート
- 過去のレポートや文書からのデータ抽出
データ収集にあたっては、データ品質やデータセキュリティにも注意する必要があります。
データ収集を行う際には、次の点に注意してください。
- 問題に関連するデータを収集する。
- データが正確であること。
- データが最新であること。
- データが十分な量であること。
問題の定義とデータ収集は、データサイエンスのプロジェクト進行の最も重要なステップです。
データの準備
収集したデータを整形し、分析に適した形に整えます。データの準備を行う際には、次の点に注意してください。
- データの不正を検出する。
- データの欠損を補う。
- データを変換する。
- データを統合する。
- データを分析しやすい形に整える。
データの準備は、データサイエンスのプロジェクト進行の重要なステップです。具体的には以下のような方法で収集したデータを整形し、分析に適した形に整えます。
データクレンジング
データベースに含まれる不正確なデータや無関係なデータを特定し、修正するプロセスです。データクレンジングを行うことで、データの信頼性を高め、データ分析やデータ活用の精度を向上させることができます。
データ統合
複数の異なるデータソースからデータを収集し、1つのデータセットにして、一元的に管理するプロセスです。データ統合を行うことで、データの重複を排除し、精度を向上させ、データ分析やデータ活用を効率化することができます。
データ変換
データを、分析しやすいように形を変えます。例えば、データの大きさを揃えたり、テキストデータを数値データに変換(=カテゴリ変数※に置き換える)したりします。
特徴量エンジニアリング
機械学習モデルに入力するデータを、分析しやすい形に変換するプロセスです。特徴量※エンジニアリングを行うことで、機械学習モデルの精度を向上させることができます。
データサンプリング
データ量が多すぎる場合は、ランダムサンプリング※や層別サンプリング※などの方法で、その量を減らすことができます。
これらを行うことで、データのサイズを小さくしたり、データの特徴をよりよく捉えたりすることができます。
データ分割
モデルの学習と評価に用いるために、データセットをトレーニングセット※とテストセット※に分割します。トレーニングセットとテストセットを分ける理由は、機械学習モデルがトレーニングセットに過学習すると、トレーニングセットに含まれるデータにしか対応できなくなるので、これを防ぐためです。
データの分析
| 手法 | 目的 | 例 |
|---|---|---|
| 記述統計 | データの基本統計量(平均、中央値、標準偏差など)を計算し、データの特徴を把握する。 | ヒストグラムや散布図などの可視化手法 |
| 探索的データ分析(EDA) | データの特徴やパターンを探索し、仮説を立てる。 | クラスタリング、次元削減、主成分分析 |
| 機械学習 | データからモデルを構築し、予測精度を向上させる。 | 決定木、ランダムフォレスト、ニューラルネットワーク |
| 統計解析 | データ間の関係性や影響度合いを解析する。 | t検定、ANOVA、回帰分析 |
| データマイニング | 大量のデータからパターンや知見を発見する。 | アソシエーションルール学習、クラスタリング、時系列解析 |
データを可視化し、傾向やパターンを探求します。データの分析には、以下のような手法があります。
モデルの構築と評価
問題に合ったモデルを選択し、学習させます。その後、学習したモデルを評価し、性能を検証します。
モデルの構築
| 手法 | 内容 | 例 | |
|---|---|---|---|
| 機械学習モデル | 教師あり学習 | ラベル付きのトレーニングデータを用いて、モデルを構築 | 回帰分析、分類分析、ニューラルネットワークなど |
| 教師なし学習 | ラベルが付いていないデータからパターンを発見し、モデルを構築 | クラスタリング、異常検知、次元削減など | |
| 強化学習 | エージェントが環境と相互作用しながら、報酬を最大化するように学習 | Q学習、方策勾配法など | |
| 転移学習 | あるタスクで学習した知識を、別のタスクに応用 | ファインチューニング、ドメイン適応など | |
| 統計モデル | 線形回帰 | 説明変数と目的変数の関係を線形モデルで表現 | 最小二乗法などを用いて、回帰係数を推定 |
| ロジスティック回帰 | 目的変数が二値変数(0または1)の場合に使用 | ロジット関数を用いて、目的変数が1である確率を予測 | |
| 生存時間分析 | イベント発生までの時間(生存時間)を扱う統計モデル | 生存曲線分析やコックス比例ハザードモデルなど | |
| 時系列解析 | 時間的な変動を扱う統計モデル | ARIMA、VAR、VARMAなど |
機械学習モデルや統計モデルを構築し、モデルのパラメータ調整(後に解説)や特徴量選択などの最適化手法を用いて、モデルの性能を向上させます。
ハイパーパラメータの調整
ハイパーパラメータとは、機械学習のモデルが学習を始める前に設定するパラメータのことを指します。これらのパラメータは学習プロセスを制御し、モデルのパフォーマンスと学習能力に大きな影響を与えます。
一般的には、以下の手順でハイパーパラメータを調整します。
- ハイパーパラメータの候補を決定
- ハイパーパラメータの候補を組み合わせて、モデルを学習
- モデルの性能を評価
- ハイパーパラメータの候補を調整
- 2〜4の手順を繰り返す
ハイパーパラメータは、モデルがデータから自動的に学習することはできず、人間が手動で調整しなければならない設定値です。そのため、ハイパーパラメータの適切な選択と調整は、機械学習のモデルの精度を向上させるために重要なステップとなります。
モデルの評価
モデルの評価を行うことで、機械学習モデルが未知のデータに対してどの程度正しく予測できるかを判断することができます。代表的な評価指標として、以下のようなものがあります。
回帰モデル(連続値を予測するための機械学習モデル)
- 線形回帰モデル
予測したい値(目的変数)と予測に使用する値(説明変数)の間に線形の関係がある場合に使用されるモデル。例えば、広告費と売上の関係を分析する場合などに使われる。 - ロジスティック回帰モデル
目的変数が2値(成功/失敗など)の場合に使用されるモデル。例えば、ある商品を購入するかどうかを予測する場合などに使われる。
分類モデル(カテゴリ型のデータを予測するための機械学習モデル)
- 決定木(デシジョンツリーモデル)
データを分割することで、目的変数を予測するモデル。例えば、ある人が糖尿病かどうかを予測する場合などに使われる。 - サポートベクターマシン
データを分類するための境界線を決定し、新しいデータがどちらのクラスに属するかを予測するモデル。例えば、ある画像が犬か猫かを予測する場合などに使われる。
結果の可視化と報告
結果の可視化と報告を行うことで、プロジェクトの目的を達成するために必要な情報を関係者にわかりやすく伝えることも重要なステップです。一般的には、
- グラフ
- 表
- 図
- アニメーション
などの方法で結果を可視化し、
- レポート
- プレゼンテーション
- ウェブサイト
- ブログ
といった方法で結果を報告します。
データサイエンスのプロジェクト進行は、データサイエンスの中で非常に重要な要素です。データサイエンスのプロジェクト進行がうまくいかないと、データの収集や分析に時間がかかったり、間違った意思決定をしたりしてしまう可能性があります。
そのため、データサイエンスプロジェクトを成功させるためには、プロジェクトの進捗状況を常に把握し、必要に応じて調整していくことが重要です。
【データサイエンスを活用した課題解決のプロセスのイメージ】

次の章では、データサイエンスに関連する技術を紹介します。*2)
データサイエンスと関連するテクノロジー
データサイエンスは、データを収集・整理・分析し、ビジネス価値を生み出すための技術です。関連するテクノロジーを大きくカテゴリーに分けると、
- データ収集とストレージ
- データ処理と分析
- 機械学習と人工知能
- モデル展開と運用
などがあります。それぞれ具体的に見ていきましょう。
データ収集とストレージ
データ収集とストレージは、データを集め、保存するための技術です。
- データベース管理システム (DBMS)
データの集積、管理、操作を行うためのソフトウェア。 - データウェアハウス
大量のデータを高速に検索・解析するためのデータベースの一種。 - データレイク
多様な形式のデータを保存するためのストレージ。構造化データだけでなく、非構造化データも含めることができる。 - クラウドストレージ
インターネット上にあるサーバーにデータを保存するためのストレージ。
データ処理と分析
データ処理と分析は、データを集め、整理、分析するための技術です。データ処理と分析
には、以下のような技術があります。
- データ処理フレームワーク※ (Apache Hadoop, Apache Spark)
大量のデータを分散処理して、高速に検索・解析するためのソフトウェア。 - データ統合ツール
複数のデータソースからデータを収集し、一元化するためのソフトウェア。 - データ可視化ツール (Tableau, Power BI)
データをグラフやチャートなどで視覚的に表現するためのツール。 - ビッグデータ分析ツール (Python, R)
大量のデータを解析するためのプログラミング言語。
機械学習と人工知能(AI)
機械学習と人工知能(AI)は、コンピュータがデータから学習して、人間と同じように、もしくはそれ以上に、物事を判断したり、行動したりすることができる技術です。具体的には以下のような技術があります。
- 機械学習フレームワーク
機械学習モデルを開発するためのソフトウェアです。TensorFlowやPyTorchは、機械学習フレームワークの例です。 - 自然言語処理ツールキット
自然言語をコンピュータが理解・処理するために使用されるソフトウェアです。NLTKやspaCyは、自然言語処理ツールキットの例です。 - 強化学習フレームワーク
強化学習エージェントを開発するためのソフトウェアです。OpenAI GymやRLlibは、強化学習フレームワークの例です。
機械学習、自然言語処理、強化学習は、すべて人工知能の分野です。これらの技術は、さまざまな分野で応用されており、私たちの生活をより便利で豊かにしています。
モデル展開と運用
モデル展開と運用は、機械学習モデルを実際に運用するための技術です。モデル展開と運用
には、以下のような技術があります。
- クラウドプラットフォーム (AWS, Azure, GCP)
クラウド上でアプリケーションやサービスを提供するためのプラットフォーム。 - コンテナ化技術 (Docker, Kubernetes)
アプリケーションやサービスをコンテナとしてパッケージングし、効率的に展開・運用するための技術。 - モデル監視ツール
機械学習モデルの精度やパフォーマンスを監視し、必要に応じて修正するためのツール。
データサイエンスにAI(人工知能)の果たす役割
AIは、データサイエンスの関連テクノロジーの中で、
- データの収集
- 分析
- 解釈
- 結果に基づく意思決定
などを支援する重要な役割を果たしています。
AIは、データからパターンや傾向を自動的に学習し、人間よりも効率的かつ正確にデータ分析を行うことができます。また、AIは、人間の専門知識を超えた領域でも、データから有益な情報を抽出することができます。
現在ではAIは、データサイエンスのプロジェクトを成功させるために不可欠な技術で、今後の進化により、より高度なデータ分析や予測が可能になると考えられています。
例えば、自動運転車やスマートホームなどの分野でAI技術が活用されることで、より快適で安全な生活が実現される可能性があります。また、医療分野では、AI技術を使って病気の早期発見や治療法の開発が進むことが期待されています。
ただし、倫理的な問題やプライバシーの問題なども存在するため、AI技術の発展には適切な規制や倫理的な枠組みが必要不可欠です。
このように、各テクノロジーはデータサイエンスにおいて重要な役割を果たしています。ただし、必要な技術はプロジェクトや業界によって異なるため、適切な技術を選択することが必要です。
次の章では、実際にデータサイエンスが活躍する身近な事例を見ていきましょう。*3)
データサイエンスの身近な例
データサイエンスは社会や生活の中の多くの場面で利用されています。代表的な例をいくつか見てみましょう。
オンラインショッピング
オンラインショッピングサイトでは、データサイエンスを利用して顧客の行動履歴や購入履歴などのデータを収集し、データ分析を行っています。例を挙げると、Amazonは、データサイエンスを活用して、オンラインショッピングの効率化や顧客満足度の向上に努めています。
- ユーザーの過去の購入履歴や閲覧履歴を分析して、ユーザーの興味関心に合った商品を勧める。
- 商品の需要や競合他社の価格を分析して、適切な価格を設定する。
- ユーザーの興味関心や閲覧履歴を分析して、ユーザーに効果的な広告を配信する。
Amazonはこのようにデータサイエンスを活用し、ユーザーにとってより便利で快適なオンラインショッピング体験を提供しています。
銀行業務
銀行では、顧客の取引履歴やクレジットスコアなどのデータを収集・分析し、信用リスク評価やクレジットカードの不正利用検知などに活用されています。特に、データサイエンスを活用した不正取引の検出に積極的な銀行として、三菱UFJ銀行が挙げられます。
三菱UFJ銀行は、データサイエンスを駆使し、膨大な取引データや顧客の行動データを分析して、不正取引を検出するシステムを開発しています。このシステムにより、不正取引の検出率を向上させ、顧客の資産を保護しています。
医療分野
医療分野では、患者の診療履歴や遺伝子情報などのデータを収集・分析し、病気の早期発見や治療法の開発などに活用されています。データサイエンスを活用した病気の早期発見に積極的な病院として、国立がん研究センター東病院が挙げられます。
国立がん研究センター東病院は、患者の過去の診療記録や検査結果を分析して、病気の早期発見に役立てています。この取り組みにより、病気の早期発見率を向上させ、患者の病気治療後の状態を改善しています。
交通システム
交通システムでは、交通量や道路状況などのデータを収集・分析し、交通渋滞の予測や最適なルート案内などに活用されています。例えば、交通渋滞の解消では、交通量や天気などのデータを分析して、最適な交通ルートや交通手段を推奨しています。
また、交通事故を減少させるために、交通事故の発生状況やドライバーの運転行動などのデータを分析して、交通事故を防ぐための対策を立てることに役立てています。身近な例では、GoogleマップやYahoo!カーナビなどのナビゲーションアプリで、データサイエンスの技術により、交通渋滞の状況をリアルタイムで確認することを可能にしています。
スポーツ競技

スポーツ競技では、選手のパフォーマンスデータや試合の結果などのデータを収集・分析し、戦術の最適化や選手の能力評価などに活用されています。野球を例に挙げると、
- 選手の選抜:選手の過去の成績や身体能力などのデータを分析して、チームに必要な選手を選抜する。
- 戦術の立案:対戦相手のデータやチームの強み・弱みなどを分析して、最適な戦術を立てる。
- 選手の育成:選手のパフォーマンスや練習データなどを分析して、選手の弱点を克服し、強みを伸ばすためのトレーニングを行う。
- 試合の分析:試合の展開や選手のパフォーマンスなどを分析して、今後の試合に活かす。
など、データサイエンスは、野球のあらゆる場面で活用されています。
このように、現在すでに幅広い分野で活用されているデータサイエンスですが、今後は技術の進歩やインフラ整備などと共に、さらに活躍の場を広げると予想されています。次の章ではデータサイエンティストに求められるスキルを確認しましょう。*4)
データサイエンティストに求められるスキル
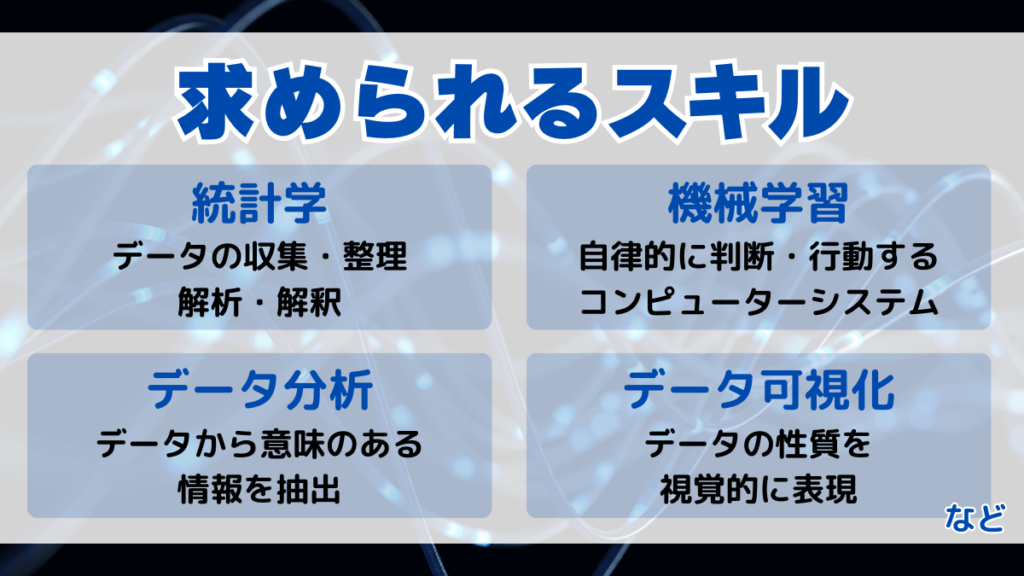
データサイエンティストは、データから意味のある情報を抽出し、ビジネスの課題を解決するために、以下のようなスキルを身につける必要があります。
- 統計学:データの収集、整理、解析、解釈
- 機械学習:データから学習し、自律的に判断・行動するコンピューターシステムを構築
- データ分析:データから意味のある情報を抽出
- データ可視化:データの性質を視覚的に表現
- プログラミング:コンピュータープログラムを記述
- データベース:データを保存・管理
- 情報工学:情報システムを設計・開発・運用
- ビジネス:企業や組織の活動に関する知識
- コミュニケーション:他人と効果的に意思疎通
- 問題解決:問題を明確にし、解決策を立案・実行
データサイエンスに必要なスキルの中には、AIに任せることができるものもあります。例えば、データの収集や整理、データベースの管理などです。また、機械学習やデータ分析などの技術は、AIがまだ発展途上ですが、今後は人間の代わりに行うようになる可能性があります。
しかし、データサイエンティストの仕事は、データの分析や解釈だけではありません。データから意味のある情報を抽出し、ビジネスの課題を解決するためには、ビジネスの知識や問題解決能力も必要です。これらのスキルは、AIがまだ完全には習得できていない領域です。
【デジタル関係のさまざまな人材とデータサイエンティスト】

データサイエンティストに資格は必要?
データサイエンティストになるために、必ずしも資格は必要ではありません。しかし、データサイエンティストとして活躍するためには、先ほど挙げたようなさまざまな知識とスキルが必要です。
これらの知識とスキルを身につけるために、大学や専門学校で学ぶこともできますし、独学で学ぶこともできます。データサイエンティストになるための資格としては、以下のようなものがあります。
- 統計検定士
- 情報処理技術者試験(データベーススペシャリスト試験、システムアーキテクト試験など)
- 機械学習技術者認定試験
- データサイエンティスト検定
これらの資格は、データサイエンティストとして活躍するための知識とスキルを証明するものです。このような資格を取得することで、就職や転職に有利になる可能性があります。
データサイエンティストにプログラミング言語は必須!
プログラミング言語とは、コンピュータに指示を出すための言語で、データサイエンスにはなくてはならない知識です。プログラミング言語には、さまざまな種類があり、それぞれに特徴があります。
データサイエンスにおいて有用なプログラミング言語はいくつかあります。以下に代表的なプログラミング言語をいくつか紹介します。
- Python(パイソン)
Pythonはデータサイエンスの分野で非常に人気のあるプログラミング言語です。シンプルで読みやすい文法や豊富なライブラリ(例:NumPy、Pandas、Matplotlib)を提供しており、データの分析や可視化、機械学習の実装などに適しています。 - R
Rは統計解析やデータ可視化に特化したプログラミング言語です。R言語はデータサイエンスの研究者や統計学者によって広く使用されており、豊富な統計関数やパッケージを提供しています。 - SQL
SQLはデータベースの操作やクエリの作成に使用される言語です。データサイエンスでは、データの取得や整形、データベースとの連携などによく使用されます。 - Julia(ジュリア)
Juliaは高速な数値計算や科学技術計算に特化したプログラミング言語です。PythonやRよりも高速な処理が可能であり、大規模なデータセットや高度な数値計算を行う場合に有用です。
初めてプログラミングを学ぶ場合は、Pythonがおすすめです。Pythonは学習コミュニティが大きく、初心者にも優しい言語です。
データサイエンティストに必要なスキルを確認したので、次の章ではデータサイエンティストになるための方法を紹介します。*5)
データサイエンティストを目指せる!データサイエンス学部がある大学
日本国内でデータサイエンスを専門的に学べる学部を持つ大学を3つ紹介します。
秋田大学 – 情報データ科学部
秋田大学の情報データ科学部は、2025年4月に新設される学部で、情報学とデータサイエンスを融合した教育を目指します。
この学部では、プログラミングや統計学、AI技術といった基礎スキルを徹底的に学ぶことができ、地域課題の解決に特化した実践型カリキュラムが特徴です。
1~2年次には情報学やデータサイエンスの基礎を幅広く学び、3年次以降は応用分野に進むことで、各自の興味やキャリア目標に応じた専門性を深められます。
地域社会でのデータ活用や防災・エネルギー問題への応用を重視していることから、卒業研究では実際の社会課題に取り組め、地方創生や地域密着型の課題解決に興味がある学生に特におすすめです。
宇都宮大学 – データサイエンス経営学部
宇都宮大学のデータサイエンス経営学部は2024年4月に設立された新しい学部で、データサイエンスと経営学を融合させた教育を展開しています。
この学部では、地域産業の発展を支える人材育成を目指し、データ分析力と経営戦略構築力を兼ね備えた「次世代型リーダー」を育てます。
1~2年次には共通科目としてデータサイエンスと経営学の基礎を学び、その後は「データサイエンス系」または「経営系」のどちらかを選択して専門性を深めます。
また、企業との連携による実践的なプロジェクトやインターンシップも充実しており、ビジネス現場で即戦力となるスキルを身につけることができます。文系・理系問わず多様なバックグラウンドの学生が活躍できる環境が整っています。
明星大学 – データサイエンス学環
明星大学のデータサイエンス学環は2023年4月に誕生した新しい教育形態で、「学部」でも「学科」でもない「環状型」のカリキュラムが特徴です。
この学環では、理工系から文系まで幅広い分野とデータサイエンスを結びつけた包括的な教育が行われています。数理科学・統計学・情報学を基盤としながらも、AIやビッグデータ分析など最新技術の実践的な応用方法も習得可能です。
また、「AI・機械モデル」「地球・都市環境モデル」「ファイナンス・FinTechモデル」など、多様な専門分野に応じたカスタマイズ可能なカリキュラムが用意されており、自分だけのキャリアパスを設計しながら社会課題解決に貢献するためのスキルを磨ける学環です。
データサイエンティストになるためには
先ほど確認したように、データサイエンティストになるためには、
- プログラミング言語のスキル
- データ分析のスキル
- 統計学の知識
- 問題解決能力
- コミュニケーション能力
などのスキルが必要です。これらのスキルを身につけるために、大学でデータサイエンスを学ぶ方法や、講座や本で勉強する方法などがあります。
文系の人もデータサイエンティストになることができます。ただし、数学や統計学の基礎知識は必要です。
また、データサイエンティストになるためには、継続的な勉強が必要です。常に新しい技術や知識を身につけていくことで、データサイエンティストとして活躍することができます。
データサイエンス習得コースの例
【総務省統計局が提供する社会人のためのデータサイエンス入門】

総務省統計局は、データサイエンス人材の育成を目的として、データサイエンス習得プログラムを実施しています。このプログラムは、データサイエンスの基礎知識から応用的な知識までを学ぶことができます。
データサイエンス習得プログラムは、以下の3つのコースに分かれています。
- 社会人のためのデータサイエンス入門
- 社会人のためのデータサイエンス演習
- 誰でも使える統計オープンデータ
総務省統計局のデータサイエンス習得プログラムは、無料で受講することができます。受講期間は一般的に1年から3年程度です。
このほかにも、経済産業省などからIT人材育成のための講座が提供されています。
【経済産業省が提供する「マナビDX」】

データサイエンスを学ぶ初心者が陥りやすい失敗
データサイエンスには多様なスキルが求められます。一般的に初心者が陥りやすい失敗の例を確認して、あなたが学ぶときは、十分に気をつけましょう。
数学や統計の基礎を十分に理解せずに進んでしまう
データサイエンスは数学や統計の概念に基づいています。初心者がこれらの基礎を飛ばして実践に入ろうとすると、後で理解が追いつかなくなる可能性があります。十分な数学と統計の基礎を学ぶことは、データサイエンスの学習の基盤となります。
プログラミングの重要性を軽視してしまう
データサイエンスではプログラミングが必須です。初心者がプログラミングの重要性を軽視し、プログラミングスキルを磨かないと、データの前処理やモデルの構築などのタスクが困難になる可能性があります。プログラミングの基礎を身につけることは、データサイエンスの学習において不可欠です。
実践を怠ってしまう
データサイエンスは実践によって学ぶことが重要です。理論や概念を学ぶだけでは、実際の問題に対して適用するスキルを身につけることができません。実際のデータセットやプロジェクトに取り組むことで、データサイエンスの手法やツールを実際の問題に適用する経験を積むことが大切です。
データサイエンティストに向いている人の特徴

データサイエンスに向いている人の特徴は、以下のとおりです。
| 特徴 | 内容 |
|---|---|
| 論理的思考力 | 因果関係を正しく捉え、データを根拠に考察できる力 |
| 問題解決力 | 複雑な課題をデータで整理し、最適解を導く力 |
| データ分析力 | 統計や可視化を駆使して意味のある情報を抽出する力 |
| プログラミング力 | Python・R・SQLなどを活用して効率的に分析する力 |
| コミュニケーション能力 | 非技術者にわかりやすく説明し、連携できる力 |
| 英語力 | 海外の文献や最新研究を理解し、共有できる力 |
| 好奇心 | 「なぜ?」を追求し、新しい手法を試す意欲 |
| 向上心 | 常に学び続け、最新技術を取り入れる姿勢 |
| チームワーク | エンジニアやビジネス部門と協働する力 |
| 学習意欲 | 独学や実践を通じてスキルを高め続ける姿勢 |
論理的思考力
データサイエンティストには、データの因果関係や傾向を正しく読み解く論理的思考力が不可欠です。
例えば、A/Bテストの結果を分析する際、単なる相関ではなく「なぜその結果になったか」を数学的・統計的に考察する必要があります。
また、ビジネス課題を数値モデルに落とし込む際にも、前提条件や仮説を明確に定義する論理性が求められます。
プログラミング力
PythonやRなどの言語を使いこなし、データ処理・分析を効率化するスキルが必須です。
例えば、Pandasライブラリでデータクリーニングを行ったり、Scikit-learnで機械学習モデルを構築したりします。また、SQLを用いて大規模データベースから必要なデータを抽出する能力も重要です。
プログラミング力が高いと、反復作業を自動化し、分析のスピードと再現性を向上させられます。未経験者でも、オンライン教材やBootcampで習得可能です。
コミュニケーション能力
分析結果を非技術者(経営層・マーケティングチームなど)にわかりやすく伝える力が求められます。
例えば、複雑な統計モデルをビジネスインパクトに変換し、「どの施策が売上に寄与したか」を簡潔に説明する必要があります。プレゼンテーションやレポート作成の際には、グラフやストーリーテリングを活用し、相手の理解レベルに合わせて調整します。
また、プロジェクトの関係者と協力する際の傾聴力や質問力も重要です。
好奇心
「なぜ?」を追求する好奇心は、データサイエンティストの原動力です。
例えば、ECサイトの離脱率が高い理由を調べる際、単なるデータの表面だけでなく、ユーザーインタビューや競合調査まで掘り下げる姿勢が重要です。
好奇心が強い人は、新しい分析手法(深層学習・自然言語処理など)にも積極的に挑戦し、業務に応用できます。
データサイエンスを学ぶメリット
【特にデジタル人材を必要とする部門】

【デジタル人材の充足状況】

データサイエンスを学ぶことは、学生や社会人にとって多くのメリットをもたらします。日本ではデータサイエンティストなどの、「デジタル人材」が社会全体として見ても不足していると言われています。
上の円グラフからも、データサイエンティストなどのデジタル人材は社会的な需要が高いと言えます。それだけでなく、データサイエンスを学ぶことは、個人としても以下のようなメリットがあると考えられます。
キャリアの多様性
データサイエンスのスキルは、
- 金融
- ヘルスケア
- テクノロジー
- 小売
- エンターテイメント
など、多様な産業で活用できます。これにより、興味や専門性に合わせてキャリアを選ぶ柔軟性が得られます。
問題解決能力の向上
データサイエンスは、複雑な問題を解決するためのアプローチを学ぶため、問題解決能力を大幅に向上させることができます。これは、ビジネスだけでなく日常生活においても有用なスキルです。
高収入
データサイエンスの専門家は、その高度なスキルと知識により、一般的に高い給与を得ることができると言われています。
将来性
データは今後も増え続けると予測されており、その解析と解釈が重要となるため、データサイエンスのスキルは将来性があると言えます。
知識の深化
データサイエンスを学ぶことで、統計学、プログラミング、機械学習など、様々な分野の知識を深めることができます。
このように、データサイエンスを学ぶことは、個々のキャリアやライフスキルの向上に大いに役に立つと言えます。一般的な社会人が仕事をしながらデータサイエンスを習得するには、平均して1年から3年程度かかると言われています。(学習時間や学習方法、個人の能力によって習得にかかる時間は異なります。)
次の章では、データサイエンスの抱える課題や問題について確認しましょう。*7)
データサイエンスの課題
現状、データサイエンスには、以下のような問題や課題があります。
データの品質と信頼性
データサイエンスの分析やモデリングは、正確なデータに基づいて行われる必要があります。しかし、データの品質や信頼性には課題があります。データが欠損していたり、誤った情報が含まれていたりする場合、分析結果や予測モデルの信頼性が低下します。
データのプライバシーとセキュリティ
データサイエンスの活用には大量のデータが必要ですが、個人情報や機密情報が含まれる場合があります。データのプライバシーとセキュリティを保護するための適切な対策が必要です。また、データの不正アクセスやハッキングのリスクも考慮する必要があります。
解釈可能性と説明性
データサイエンスのモデルやアルゴリズムは、複雑な数学や統計の手法を使用しています。そのため、その結果や予測がどのように導かれたのかを解釈することが難しい場合があります。特に、ブラックボックス※と呼ばれるモデルでは、その結果を説明することが困難です。
偏りとバイアス
データサイエンスでは、データを分析して予測や意思決定を行いますが、データには、偏りやバイアスが含まれていることがあります。
- 偏り=データに含まれている誤差や不正確さ
- バイアス=データに含まれている主観的な判断や価値観
のことです。偏りやバイアスが含まれていると、データ分析の結果に誤りが生じてしまうことがあります。このことが原因で、特定のグループや属性に対して、不公平な結果が出る可能性があります。
このようなバイアスを排除するために、データサイエンティストには適切なデータの収集やモデリング手法の選択が求められます。
これらのデータサイエンスにおける問題や課題に対処するためには、
- データの品質管理
- セキュリティ対策の強化
- モデルの解釈可能性の向上
- バイアスの排除
など、様々な取り組みが必要です。また、倫理的な観点や社会的な影響も考慮しながら、データサイエンスを活用することが重要です。
次の章ではデータサイエンスとSDGsの関係について考えてみましょう。*8)
データサイエンスに関するよくある質問
データサイエンスに関するよくある質問を集めました。
データサイエンスは挫折率が高いのは本当?
データサイエンスは多くの専門的な知識を必要とする分野で、時には習得の途中で挫折感を感じることがあります。挫折感を感じる代表的な理由は以下の通りです。
- 幅広いスキルセットが必要
データサイエンスは、数学、統計学、プログラミング、データ管理、ビジネス知識など、多くの異なるスキルを必要とします。これら全てをマスターするのは大変な労力が必要です。 - 複雑なツールと技術
データサイエンスには、PythonやRといったプログラミング言語、SQLといったデータベース言語、さらには機械学習アルゴリズムなど、多くの複雑なツールと技術が関わってきます。これらを理解し、適切に使用することは容易ではありません。 - 現実のデータは決してきれいではない
理論的な学習から実際のデータ分析へ移行すると、データが決してきれいに整っていないことに直面します。データのクリーニングや前処理は時間と労力を必要とし、これも折感を生む一因となります。 - 結果の解釈とコミュニケーション
データから洞察を得るだけでなく、それを他の人に説明する能力も必要です。これはデータサイエンスの重要な部分であり、このスキルが不足していると挫折感を感じることがあります。
しかし、これらの挑戦を乗り越えることで、データサイエンスは非常に報酬の高いキャリアとなります。次の章では、データサイエンスを学ぶメリットをまとめます。*6)
データサイエンスは独学でも学べる?
データサイエンスは独学で習得可能です。数学・統計学の基礎知識やプログラミングスキル(特にPython)が必要ですが、オンライン学習サイトや書籍を活用することで体系的に学べます。
独学のメリットは費用を抑えられることですが、モチベーション維持が課題となるため、学習計画を立てることが重要です。
(1)統計学の基礎、(2)Pythonプログラミング、(3)機械学習の順に進めるのが一般的です。
データサイエンス入門するならどこがおすすめ?
初心者にはオンライン学習プラットフォームが適しています。
動画教材やインタラクティブな演習問題を備えたサイトでは、実践的なスキルを段階的に習得可能です。大学の講座も選択肢の一つで、順天堂大学などではデータサイエンスの理論から応用までをカリキュラムに組み込んでいます。
時間に制約がある社会人向けには、週末や夜間に対応したスクールも増えています。
データサイエンスを学ぶのにおすすめの本や講座はある?
入門者向け書籍では、数学的基礎を解説した理論編とPython実践編に分かれたものが人気です。
講座選びのポイントは、以下の3点です。
- 統計学の基礎を含むか
- プログラミング演習があるか
- 実務的なケーススタディを扱っているか
資格取得を目標に据えると学習のモチベーション維持に効果的で、基礎レベルの認定試験から始めるのがおすすめです。
データサイエンス学部はやめとけと言われるのはなぜ?
データサイエンスがやめとけと言われる主な理由として、以下があります。
- 学習難易度が高い
- 求められる専門性が幅広い
- 泥臭い作業が多い
- 学問・技術の進化が早く、学び続ける必要がある
データサイエンティストはデータ収集や分析・前処理(データクリーニング)など、地道な作業を膨大にこなす必要があります。また、学習難易度が高いうえに、トレンドが数年単位で変わるため学び続ける必要がある点もデータサイエンスの特徴です。
そのため、データサイエンス学部を「楽に就職できそう」などの理由で選ぶと、失敗する可能性があります。
データサイエンスとSDGs
データサイエンスとSDGsの関係は、すぐにはイメージしにくいかもしれません。しかし、データサイエンスの技術は、SDGsの目標達成に貢献することができます。
例えば、データサイエンスを活用することで、貧困、飢餓、不平等、気候変動などの問題を解決するための解決策を導き出すことができます。また、データサイエンスを活用することで、効果的な政策やプログラムを策定・実施することができます。
具体的に見ていきましょう。
政策立案と戦略策定
データサイエンスは、政策立案や戦略策定において、データに基づいた意思決定を支援するために役立ちます。例えば、SDGsの目標1「貧困をなくそう」を達成するためには、貧困に苦しむ人々の数や、貧困の原因をデータで分析する必要があります。
そして、そのデータを分析した結果に基づいて、貧困をなくすための政策や戦略を立案することができます。
社会や環境の課題の特定と優先順位付け
データサイエンスは、社会や環境の課題を特定し、優先順位付けするのに役立ちます。例えば、SDGsの目標11「住み続けられるまちづくりを」を達成するためには、都市化の進展による人口増加や、気候変動による環境問題などの課題を特定する必要があります。
データサイエンスによって、その課題を特定した結果に基づいて、解決するための政策や戦略を立案することができます。また、データの分析により、貧困の地域や環境問題の深刻度を把握し、必要な物を効果的に配分することが可能です。
SDGsの進捗状況のモニタリングと評価
データサイエンスは、SDGsの進捗状況をモニタリングし、評価するのに役立ちます。
具体的には、次のようなものが挙げられます。
- SDGsの目標やターゲットに関するデータを収集・分析する
- SDGsの進捗状況を可視化する
- SDGsの進捗状況の課題を特定する
- SDGsの進捗状況の評価を行う
データの収集や分析により、SDGs目標の達成度や進捗状況を数値に置き換えて評価することができます。
イノベーションと技術の活用
データサイエンスは、新たなイノベーションや技術の開発にも貢献します。データの分析や機械学習の手法を活用することで、持続可能なエネルギーの開発や環境保護など、新たな解決策や技術の創出が可能になります。
データサイエンスの手法や技術を活用することで、SDGsの達成に向けた効果的な取り組みが可能になります。データサイエンスはSDGsの実現に貢献する重要な手段なのです。
まとめ
データサイエンスは、将来にわたって需要が高まると予測されています。データの分析や活用能力は、現代社会においてますます重要となっています。
データサイエンスの学習は、自身のスキルを向上させ、将来のキャリアにおいて競争力を持つための効果的な手段です。データに基づいた意思決定や問題解決能力を身につけることで、さまざまな業界や社会の課題に対して貢献することができます。
この記事を読んで、さらに興味がわいたならぜひ、データサイエンスの学習に挑戦してみてください!
〈参考・引用文献〉
*1)データサイエンスとは
内閣府『デジタル人材の育成・確保に向けて』p.2(2022年2月)
IBM『データサイエンスとは』
Harvard Business Review『Data Scientist: The Sexiest Job of the 21st Century』
デジタル庁『データ戦略の推進状況』(2022年9月)
*2)データサイエンスのプロジェクト進行について
経済産業省『Society5.0実現に向けたデータサイエンティスト育成について』p.7
経済産業省『デジタルスキル標準 ver.1.0』(2022年12月)
NTT PC Communications『データサイエンスチームのプロジェクトマネジメント』(2018年6月)
IBM『データサイエンスとは』
*3)データサイエンスと関連するテクノロジー
Apple『機械学習とAI』
日本経済新聞『データサイエンスとは 専門人材、世界で需要高まる』(2023年2月)
Softbank『テクノロジーが導く未来を体験。ソフトバンク 先端技術研究所の技術展「ギジュツノチカラ ADVANCED TECH SHOW 2023」レポート』(2023年4月)
*4)データサイエンスの身近な事例
IBM『データ分析とAIドリブン分析』
総務省『ビッグデータの活用が促す成長の可能性』
総務省『デジタルデータの経済的価値の計測と活用の現状に関する調査研究の請負』(2020年3月)
経済産業省『中東欧5カ国IT 産業及び人材に関する現地調査レポート』(2023年2月)
日経リサーチ『DATA SCIENTIST日経リサーチのデータサイエンティストとは』
Amazon『データサイエンスとは』
日本経済新聞『三菱UFJ銀行、生成AIを110業務で導入 手続き照会など』(2023年6月)
日本経済新聞『三菱UFJ、サイバーエージェントと広告事業 データ活用』(2022年7月)
日本経済新聞『三菱UFJ銀、窓口業務7割デジタル化 米銀は無人店も 大手行、問われる速度』(2023年6月)
日本経済新聞『TIS、国立がん研究センター東病院とITを活用し患者の潜在的な症状をデータとして抽出するための共同研究を開始』(2022年1月)
国立がんセンター東病院『データサイエンス部』
Google『データドリブンのスタイル設定を発表: Google マップの行政界情報をスタイル設定して、必要な情報を的確に伝える』(2022年6月)
日本経済新聞『グーグルマップに鉄道の現在位置 オープンデータ活用』(2021年2月)
YAHOO!JAPAN『Yahoo!カーナビ、走行データを活用し東京2020大会を見据えた交通量の調査結果を公開」(2019年8月)
YAHOO!JAPAN『ヤフーのVPoEが語る「UXのシームレス化」を目指す検索体験とローカル情報提供の質向上とは』(2022年11月)
総務省『第9回 ビッグデータ等の利活用推進に関する産官学協議のための連携会議議事概要 』(2020年2月)
DNA×AI『テクノロジーを活用した横浜DeNAベイスターズ選手の強化施策』
国立研究開発法人 科学技術振興機構『データサイエンス分野からのスポーツへの関わり』(2021年)
東京新聞『高校球児もデータサイエンスを駆使 「頭を使って実力差を埋める」進学校の挑戦』(2023年2月)
*5)データサイエンティストに求められるスキル
経済産業省『デジタルスキル標準 ver.1.0』p.9(2022年12月)
日経XTECH『5分でわかるデータサイエンティストの基礎知識』
日本経済大学『数理・データサイエンス・AIリテラシープログラム』
経済産業省『経産省におけるデジタル⼈材育成の取組状況について』(2023年6月)
*6)データサイエンティストになるためには
総務省『社会人のためのデータサイエンス入門』(2023年6月)
経済産業省『IT人材の育成』
Microsoft『データ サイエンスとは』
Microsoft『データ サイエンティスト』
*7)データサイエンスを学ぶメリット
経済産業省『「人材育成」を通じた生産性向上・人材不足対策の推進』(2017年12月)
総務省『第1部 特集 ICTがもたらす世界規模でのパラダイムシフト 第4節 本格的なデータ活用社会の到来』
総務省『データ利活用の促進』
経済産業省『データ利活用のポイント集』
*8)データサイエンスの課題
総務省『データ流通・利活用における課題 安心・安全なデータ流通・利活用環境整備の必要性』
経済産業省『令和2年度我が国におけるデータ駆動型社会に係る基盤整備(デジタル人材政策に関する調査)』(2021年3月)
IPA『デジタル時代のスキル変革等に関する調査(2022年度)全体報告書』(2023年4月)
内閣府『デジタル人材の育成・確保に向けて』(2022年2月)
SHARE

この記事を書いた人
松本 淳和 ライター
生物多様性、生物の循環、人々の暮らしを守りたい生物学研究室所属の博物館職員。正しい選択のための確実な情報を提供します。趣味は植物の栽培と生き物の飼育。無駄のない快適な生活を追求。
生物多様性、生物の循環、人々の暮らしを守りたい生物学研究室所属の博物館職員。正しい選択のための確実な情報を提供します。趣味は植物の栽培と生き物の飼育。無駄のない快適な生活を追求。




